What is DynamoDB
2004년 아마존에서 데이터량이 증가함에 따라, 2007년 Dynamo라는 논문이 발표가 됨.
2016년도 아마존에서 Tier 0 서비스에 DynamoDB를 사용하고 있음.
DynamoDB 구성은 라우팅 서비스, 다이나모디비 인스턴스, S3 다른 Database들이 포함된 형태로 구성되어 있다.
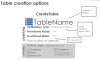
Key-Value 기반의 NoSQL Database.
![]() ![]() 스키마Less
Partition Key를 가지고 있다. –> 분산이 된다.
Sort Key를 가지고 있다. –> 정렬이 된다.
Partition Key + Sort Key => 식별Key가 된다.
index가 존재한다.
로컬 세컨드리 인덱스
글로벌 세컨드리 인덱스
Read Capacity Unit -> 읽기 처리 용량
Write Capacity Unit -> 쓰기 처리 용량
ex)
partition = 10개
Ready = 10개
Write = 10개
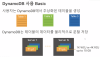 데이터는 파티션 개수 만큼 균등해서 데이터가 저장된다.

40년 전에는 메모리 용량이 작았고, 시스템 성능이 낮았다.
그렇기 때문에 중복된 데이터를 최소화하고 분리해서 애플리케이션에서는 SQL의 Join이라는 명령어를 이용하여 데이터를 조회하기 시작한다.
 NoSQL 에서는 그림 처럼 도큐멘트 형태로 데이터를 구성해서 사용한다.
기존 SQL 처럼 정규화해서 하는 것이 아닌, 고객이 넘겨주는 데이터를 그대로 받아서 사용을 할 수 있다.
 DynamoDB는 데이터 1개가 입력되면 3개로 복제되어 저장된다. (3개의 데이터 센터 등으로 복제되어 저장됨)
 오토 스케일링을 지원한다.
 DynamoDB는 완전 관리되는 서비스라고 할 수 있다.
보안
 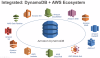 다이나모 디비는 AWS 다른 플랫폼들과 생태계 구축이 가능하다.
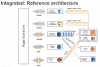
DynamoDB의 근원
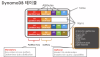 attribute 는 RDB에서 Column으로 생각하면 된다.
 파티션 키는 유니크한 값을 이용해서 적용하는 것이 좋다.
정렬키는 캐릭터나, 아이템 등으로 나누는 것이 좋다.(?)
   Local Secondary index(LSI)
테이블에 같이 존재하는 Index.
실제 데이터를 조회할 때 Sort Key를 이용해서 조회가 가능하다.
Index에 들어가는 key를 지정하는 방법은 LSIs 설정으로 지정할 수 있다.
KEYS_ONLY <– 키 기준
INCLUDE A3 <– 사용자 임의 기준
ALL <– 전체로 잡음
인덱스를 많이 잡으면 LSI 구성으로 인한 용량을 초과할 수 있기 때문에 제한사항이 있다.
 GSI는 복제를 위한 Index이다.
GSI도 LSI 처럼 동일하게 설정이 가능하다.
KEYS_ONLY <– 키 기준
INCLUDE A3 <– 사용자 임의 기준
ALL <– 전체로 잡음
테이블 용량은 기존 테이블 용량만큼 들어간다.
   다이나모 디비는 1개 데이터가 400kb로 제한할 때, 이 데이터가 나타내는 애트리뷰트 이름도 같이 용량에 포함된다. 따라서 간단한 이름을 지정할 것을 추천한다.
   On-Demand Mode는 비싸다.
On-Demand Mode와 Provisioned Mode 는 언제 써야 하나.
신규 오픈 할 땐 On-Demand Mode를 사용하고, 일정 시점 이후로 모니터링된 결과를 바탕으로 Provisioned Mode를 사용하면 좋을 것 같다.
 실제적으로 오토스케일링을 지원할 땐, 앞에서 지연되는 것을 허용하는 애플리케이션 구성이 필요하다.
Write = 1000 이고 파티션이 100이면 10개씩 나눠서 할당되는데, 일정 파티션으로 데이터가 몰리게되면 처리되는 시간이 지연될 수 있다.
특정 파티션에 데이터가 몰릴 때가 문제가 될 수 있다.
이런 경우 처리할 수 있는 방법이 있다.
 Capacity 용량을 저축했다가 사용할 수 있는 기능을 Burst 라고 칭한다.
 병목현상 문제는 DynamoDB에서는 발생 안해야 될 거 같은데 이런 문제가 생기는 현상.
Provisioned Mode보다 더 많은 요청이 들어오면 발생하게 되는데, 이럴 경우 500에러가 발생된다.
이런 경우 특정 파티션 키로 몰리게 되면 이런 현상이 발생될 수 있다.
예를들면, IoT 장비 데이터를 저장한다고 할 때, 특정 장비에서 데이터가 많이 발생하게 되면 특정 파티션만 부하가 걸릴 수 있다.
이럴 경우 파티션 Key를 논리적으로 나눠주던가, 잠시 동안 Provisioned 모드에서 On-Demand 모드로 변경해서 사용하는 것을 추천한다.
실시간적으로 모드를 변경이 가능하고, 적용 속도가 빠르다고 한다.
 TTL 데이터의 생존 시간
지워지는 데이터를 DynamoDB Stream을 이용하여 RedShitf나 S3로 저장이 가능하다.
실시간적으로 데이터를 삭제하게 되면 시스템적 부하가 큰데, TTL을 걸어두면 이런 경우를 회피할 수 있다.

 최대 3000RCU, 1000WCU를 초과하지 않도록 파티션 키를 설계하는 것을 추천한다.
그리고 이러한 모니터링은 Cloud Watch를 이용하여 벤치마킹이 가능하다.
특정 파티션에 요청이 모이게 되면, 다른 파티션에서 할당되지 않은 만큼의 Control Unit을 가져와서 성능 향상을 할 수 있도록 적용된다.
 최종적인 일관성 유지 설정 부분이 더 자원을 효율적으로 사용한다고 한다.
 1개 계정으로 사용하게 되면, 퍼포먼스 제약이 걸릴 수 있다.
대용량 데이터를 처리할 경우, 1개 계정으로는 DynamoDB 테이블을 만들어서 사용하는 것은 바람직하지 않다.
   