CQRS
CQRS를 언제, 왜, 그리고 어떻게 사용할 것인가?
기본적인 모티베이션은 무엇인가?
왜 CQRS인가?
엔터프라이즈 엔터프라이즈를 개발할 때 CRUD를 기반으로 개발을 하고 있다.
Create, Read, Update, Delete 라는 모델인데, 현재 시스템에 대한 현재 상태를 가지고 있고
현재 상태는 모든 비즈니스와 도메인 엔티티 객체의 상태를 가지고 있는 것을 말한다.
굉장히 쓰기 읽기 업데이트에 대한 일관성을 가질 수 있다.
이러한 방법은 기본적인 엔터프라이즈 애플리케이션을 개발하기 위한 것이다.
이러한 방법은 단점이 있다.
첫번째 재현성(사물이나 현상 따위가 다시 나타날 수 있는 성질.)이다.
사용자 계정 오브젝트가 있을 경우, 새로운 사용자 정보를 저장할 경우, 상태를 변경할 경우 이력 정보를 잃어버리게 된다. 이렇기 때문에 재현성을 유지할 수 없다.
두번째 일관성이다.
일관성을 유지하기 위해서 트랜잭션 간의 경합이 발생된다.
예를들어, 사용자 계정을 수정하면서 다른 정보도 수정하기 위한 트랜잭션을 넣게 되면 이러한 것들을 전부 트랜잭션을 유지하기 힘들고, 동기화를 시켜야 하기 때문에 확장성에 제한이 발생하게 된다.
그리고 여러대의 서버가 있는 경우 데이터베이스는 1개로 유지되게 되는데 이러한 경우 확장성이 제한되게 된다.
두가지 모티베이션(동기)은 첫째로 이벤트 소싱이다.
이벤트 소싱은 애플리케이션을 현재 상태, 즉 아토믹 이벤트로 현재 상태를 도출해내는 방법이다.
데이터베이스를 수정하는 행위 들을 이벤트 단위로 나누게 되면, 트랜잭션 단위로 상태를 저장할 수 있다.
그러면 나중에 전체 히스토리 이력을 가질 수 있고, 이것을 가지고 최종적으로 일관성을 유지할 수 있다.
이벤트 기반으로 하게 되면, 통계성 데이터를 산출해 낼 수 있다. 그리고 이렇게 발생된 운영 이벤트 데이터를 통해 테스트 데이터로도 사용할 수 있다.
이러한 통계 정보들을 기반으로 하게 되면 이런 이벤트 기반으로 월요일날 사람들이 많이 구매하는 상품이 무엇인지 통계를 내거나 계산하는데 도움을 줄 수 있고, 추가적으로 새로운 유즈케이스를 요청해도 이 정보들을 통해 대응할 수 있다.
그러나 이것은 일관성이나, 확장성을 유지할 수 없다.
이것을 모두 유지하기 위해서는 이벤트 드리븐 아키텍처이다.
실제 세계에서는 궁극적인 일관성을 가지게 된다.
식당에 들러서 사용자가 버거를 웨이터에게 주문하게 되면, 이러한 경우는 일관성을 유지되엇다고 하지 않습니다.
왜냐하면 주문을 접수 받은 웨이터가 조리사에게가서 버거를 주문 받을 수 있냐고 물었을 경우 불가능 하다고 답하게 되면, 이 내용을 사용자에게 다시 안내를 해주는 방식으로 동작한다.
이런 것이 궁극적인 일관성이라 말할 수 있다.
이벤트 드리븐 아키텍처는 여러가지 시스템이 있다는 것이고, 그것은 분산시스템이라 말할 수 있다.
이 시스템들은 서로 이벤트를 통해서 처리가 된다.
여러개의 트랜잭션이 발생되는 것이며, 하나의 주문이 여러개의 트랜잭션으로 나뉘게 된다. 즉, 분할 된다.
이러한 것들을 다 이벤트 단위로 나눌 수 있다는 것이다.
실제 커피숍에서는 이러한 형태로 주문이 이뤄질 것이다.
 이러한 경우 모든 이벤트는 매우 안정적으로 이벤트가 발생되어야 한다는 것이다. 일부 이벤트가 전달이 되지 않아서 아무 일이 발생되지 않게 되면, 문제가 될 수 있다. 비동기식 방식으로 궁극적으로 일관성을 가지게 되고, 확장성을 가져갈 수 있다.
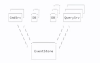
CQRS는 아래와 같다.
 이것은 쓰기와 읽기를 분리할 수 있다는 것이다.
커멘드는 어떤 값을 바꿀 수 있는 이벤트이고,
쿼리는 어떤 값을 조회하는 이벤트이다.
커멘드는 데이터 리턴을 하지 않는다. 즉 데이터를 바꾸기만 한다.
쿼리는 데이터를 읽기만 한다.
말로는 단순하고 쉽지만, 기업에 가지는 영향은 매우 크다.
커멘드는 void 메서드를 활용한다.
 커피 주문을 이 화면을 이용해서 나타내면
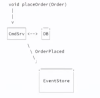 커멘드 서비스는 주문을 받고, 데이터를 저장하고, 이벤트를 발행합니다.
두번째 단계는 이 이벤트가 쿼리시스템에서 소비하는 것이다.
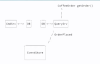 커피 주문을 리턴해야 한다.
커멘드 쪽에서 쓰기를 하고 쿼리 서비스에서 읽기를 한다.
그리고 이벤트 스토어에 이벤트들이 저장된다.
이것이 CQRS의 기반이다.
CQRS는 여러가지를 해결할 수 있다.
 확장성을 가져갈 수 있고, 느슨한 결합이고, 비동기식 이벤트 기반으로 커뮤니케이션을 한다.
여러개의 시스템이 있고, 이벤트가 들어갈 때마다 호출이 이뤄진다.
그리고 독립성을 유지할 수 있다.
읽기(Query 서버) 쪽은 훨신 더 많은 요청이 들어가게 된다.
이런 읽기를 담당하는 서비스를 높은 성능을 낼 수 있도록 확장할 수 있다.
이런 시스템은 모두 독립적이기고 이벤트 스토어에 의존적이기 때문에 각각 서비스에 최적화를 할 수 있다.
또한, 이벤트 소싱 확장성 문제도 해결 할 수 있다.
상태값을 표현한다는 것은 현재 상태 값을 데이터베이스에 저장한다는 것이다.
이것은 임시적인 것이고, 빠르게 데이터를 리턴할 수 있다.
이건 계산을 하지 않는 정보이기 때문이다.
기존 crud 기반 서비스는 1개의 데이터베이스가 존재하고, 이것에 장애가 발생되면 모든 시스템에 장애가 발생된다.
CQRS에서는 읽기와 쓰기 데이터베이스가 분리되어 있기 때문에 특정 데이터베이스에 장애가 발생되더라도 전체 장애가 발생되지 않는다.
분산 시스템이 아니라면 CQRS를 쓰지마라, 오버헤드가 크기 때문이다.
어려 데이터 베이스를 동기화 하는 방법은 CQRS는 동기화를 하지 않는다.
커멘드 요청과 동시에, 조회 가능한 URL을 응답값에 제공해준다.
여담.
음 좀 인상깊은 내용으로는 카프카에 저장했기 때문에 서버를 재시작해도 일관성이 유지되는 대목이다.
새로 처음부터 다시 읽어서 메모리에 저장해서 최종 상태를 만든 것인지 확인이 필요할 것 같다.