마이크로서비스의 패턴언어
본문 링크
패턴 언어의 역사
![]() 건축가 Christoher Alexander 집이나 마을을 설계할 때 반복적으로 활용하면 좋을, 작은 단위의 설계 패턴을 모아 정리한 것으로 시작되었다. 1977년
개발자들에게도 익숙한 언어로 되었다. 디자인 패턴
문제상황을 정리하고 정의한 다음에 해결방안을 인식하고 이 해결방안의 장점과 단점, 이 패턴과 연관되어 있는 패턴들을 인식하고, 내가 겪고 있는 문제점과 가장 비슷한 문제점들을 찾아서 먼저 해결할 수 있는 패턴들을 찾아낼 수 있다 또는 참조할 수 있다 라고 하는 것이 패턴을 활용하는 장점이다.
마이크로서비스란?

마틴 파울러는, 독립적으로 배포가 가능한 서비스를 마이크로서비스로 말한다
단일 어플리케이션에 비해서 최소 단위의 기능 단위로 분리되어 있는 것,
데이터베이스도 데이터베이스를 따로 가지고 잇는것
비즈니스 기능 중심으로 구성
상태는 외부에 보관 (stateless)
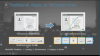
기존에는 전체 화면을 1개의 WAS(Web Applcation Server) 받아와서 처리하던 것을, Async로 화면 모듈 단위로 가져오도록 한다.
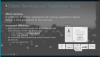 모노리틱한 구조에서 일부 서비스가 트래픽이 증가되면 전체적인 서비스에 문제가 발생된다.
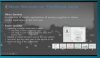 마이크로서비스로 분리하게되면, 화면 전체 중 해당되는 모듈만 독립적으로 배포 후 개선할 수 있기 때문에 전체 모듈에는 영향이 적다. 그리고 일부분의 장애가 발생되지만 전체 서비스에 장애는 발생되지 않는다.
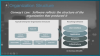 마이크로 서비스는 소프트웨어를 만드는 조직에 영향을 받는다고 한다.
수직적인 구조에서는 모노리틱한 구조의 애플리케이션이 적합하다.
 수평적인 작은 단위의 팀으로 구성하게 되면, 다양한 형태의 서비스를 구성할 수 있고 증가시킬 수 있다.
피자 두판을 같이 공유할 수 있을 정도의 팀이 마이크로서비스를 하는 단위로 효율적이다라고 한다.
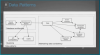
 위 그림은 넷플릭스에서 호출되는 서비스 구조를 나타낸다.
 마이크로서비스는 각각 독립된 형태로 구성되다보니, 분산 처리를 할 수 있는 환경을 만들 수 있다.
대신 복잡도가 증가된다.
마이크로서비스에서는 각각 서비스를 호출되어 latency가 증가됨에 따라, 이런 지연시간으로 인하여, 데이터 일관성에 문제가 발생될 수 있다.
이러한 형태에서는 시간이 지나면 최종적으로 일관성(Eventual Consistency)이 맞춰진다고 생각한다.
그리고 이런 내부 통신으로 REST 방식을 선택하는 것은 올바르지 않다, 차라리 바이너리 통신 방법을 도입해라
분산 환경이기 때문에 데이터가 중복될 수 밖에 없다. 마이크로서비스는 이러한 분산 환경을 그대로 계승했기 때문에 동일한 문제를 고민해야 한다.
 마이크로서비스 아키텍처에서 굉장히 유명한 분이라고 함.
해당 링크 https://microservices.io/patterns/index.html
Microservices Pattern: A pattern language for microservices
A pattern language for microservices The beginnings of a pattern language for microservice architectures. 点击这里,访问本系列文章的中文翻译 Click here for Chinese translation of the patterns Click here for PDF Application architecture patterns Which architecture should you choose for an application? Monolithic arch…
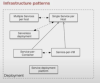
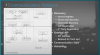
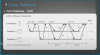
 마이크로서비스를 도입하면서 반복적으로 발생되는 문제점을 패턴화 하여 도식화한 다이어그램이다.
따라서, 이러한 다이어그램을 머릿속에 기억하는 것이 도움이 된다.
패턴 다이어그램을 보는 방법
 실선은 문제점이 되는 패턴을 해결하는 방법을 나타낸다.
점선은 어떠한 문제점에 대해 해결할 수 있는 선택지를 나타낸다.
배포 방법 고민
서비스를 디스커버리 하는 패턴
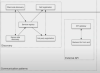 서비스끼리 통신할 때 async하게 할것인가 sync하게 할 것인가
 서비스가 장애가 발생하여 전파되는 것을 방지하는 것을 Circit Breaker 패턴
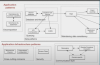 애플리케이션을 디자인할 때 어떻게 디자인할 것인가
문제영역을 어떻게 Decomposition할 것인가
비즈니스 기능에 따라 나눌 것인가
DDD에 있는 서브 도메인으로 나눌 것인가
마이크로서비스를 하면서 개발자들이 데이터베이스를 어떻게 관리할 것인지를 고민하게 되는데 그에 따른 해결 방안
서비스의 테스트 방법에 대한 고민
서비스를 어떻게 배포 할 것인가?

 컨테이너가 왜 각광을 받는가?
VM을 올리게 되면 게스트 OS가 생성이 되었었는데, 컨테이너 같은 경우는 리눅스 위에 올라가게 되고 게스트 OS가 존재하지 않아 부팅속도가 빠르다. 그리고 같은 하드웨어에 다수의 컨테이너를 올릴 수 있다.
컨테이너를 사용하면 애플리케이션을 패키징하여 배포를 할 수 있기 때문에 이식성이 굉장히 좋다. 의존성을 같이 패키징해서 올리기 때문에 개발서버에서는 안되고 운영서버에서 되던 이슈들을 해결할 수 있다.

 서비스 디스커버리에 대해서 이야기 해보면, 기존에 호스트 방식은 IP나 호스트가 자주 변경되지 않았지만, VM, Cloud, Container로 올라가게되면 IP, Host, Port가 자주 바뀌게 되는데 이러한 것을 해결하기 위한 것이 서비스 디스커버리다.
서비스 디스커버리는 클라이언트, 서버 두가지 방법이 있다.
 클라이언트 방식에는 하드웨어 없이 소프트웨어로 서비스를 디스커버리하고, 로드밸런싱을 조절한다. 이러한 로드밸런싱 로직을 커스터 마이징 할 수 있다.
단점은 이러한 서비스 디스커버리 하는 로직을 개발을 해야 한다. 각 애플리케이션 언어가 다르면 각각 개발해야 한다.
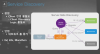 서버 방식에서는 클라이언트가 없기 때문에 쉽게 구현이 가능하다. 단점은 네트워크 대역폭이 증가된다.
 서비스 등록방법은 Self 방식과 Third Party 방식이 있다.
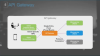 API 게이트웨이는 외부의 서비스와 내부의 서비스를 찾아내려면 프록시 같은 것이 필요하다.
API 게이트웨이는 모바일 디바이스일 때는 응답 데이터를 최소화 해주고, 특정 플랫폼일땐 맞출 수 있도록 도와주는 역할을 할 수 있다.
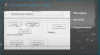 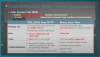 기존에 API로 설계를 하는 것은, 바깥의 서비스와 통신할 땐 유용하지만, 내부 통신 방식에서는 서로에게 오버헤드를 발생시킬 수 있다. 따라서 바이너리 방식으로 구현하는 것이 좋다. 서비스가 서비스를 호출하는 방식에서 3단계 방식을 참고해서 고려하면 좋다.
 서비스가 서비스를 호출하다보면 중간에 끼어 있는 서비스로 인하여 장애가 전파될 수 있기 때문에 이러한 문제점을 해결하기 위한 것이 서킷브레이커 패턴이다.
 서킷브레이커는 서비스가 서비스를 호출 할때 중간에서 가로채서 요청하는 서비스쪽으로 대행해서 호출한다.
이럴 경우 10초 동안 50% 이상 문제가 발생되면 서킷브레이커를 열어놓고, 일정 시간 이후에 복구가 되면 다시 닫게 된다.
마이크로서비스에서는 중요한 역할은 한다.
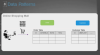
 데이터매니지먼트 패턴
마이크로서비스는 서비스 별로 데이터 스토어가 있는 것을 권고는하지만 그렇지 않아도 구현이 불가능 한 것이 아니다. 하나의 데이터베이스에서 API를 개별로 개별하다가, 서비스가 발전하면서 각각의 데이터베이스를 갖게되는 방향으로 간다.
이렇게 서비스 별로 데이터스토어를 가지게 되면, 조인(join)쿼리를 할 수 없다는 것이다.
이것을 해결하기 위한 패턴이 필요한데 이것이 CQRS이다.
데이터 일관성에서도 데이터를 같이 저장할 수 있지 않다. 따라서 이벤트 소싱을 활용해서 해결한다.
트랜잭션 로그 테일링이라는 것은, 데이터를 변경할 때 이 데이터를 캡쳐해서 발행하고, 다른 데이터 베이스로 적재하는 것이 있다.
가장 좋지 않은 방법은 데이터베이스에 트리거를 거는 것이다.
 온라인 쇼핑몰을 예로 들면, 사용자가 장바구니에 아이템을 넣어두고 주문을 할 떄, 쇼핑 카트에 들어있는 요금을 가지고 있는지 확인하고 주문을 처리하는 경우.
기존 방식은 아래와 같다.
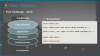 트랜잭션을 열고 각각의 데이터베이스에 데이터를 확인하고 저장하고 트랜잭션을 종료하면 일관성을 유지한체 처리가 가능하다.
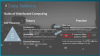
 분산 처리 방식에서는 이러한 트랜잭션을 묶을 수 없기 때문에 첫번째로 투 페이지 커밋 방식이 있다.
하지만 이렇게 될 경우 특정 데이터 레코드에 락이 걸리기 때문에 부하가 발생되어 문제가 발생될 수 있다.
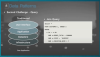
 이러한 분산환경에서는 CAP이론 처럼 3가지를 모두 만족하는 방법은 없다.
분산환경에서는 가용성을 기초로해서 가야 한다.
그리고 이벤트 드리븐, Eventual Consistency 방식으로 가야한다.
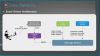
 마이크로서비스에서는 고전적인 데이터 조회 방식이 불가능하다.
 이러한 문제를 해결하는 방법은 이벤트 드리븐 방식이다.
데이터가 변경되면 해당 데이터 베이스에 저장을 하고 메시지 브로커에게 이벤트를 발행한다,
관심 있는 도메인이 그 이벤트를 받아서 데이터를 저장하고, 완료되었다는 것을 다시 발행을 한다.
이렇게 되면 최종적으로 데이터의 일관성이 만들어진다.
메시지 브로커는 카프카나 래빗엠큐 등을 활용 할 수 있다.
 쿼리를 하는 방법은 변경된 이벤트를 저장하고 이것을 기초로 뷰를 만들어낸다.
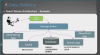
이러한 방식은 이미 여러곳에서 활용해서 사용하고 있다.
중간에 큐를 이용해서 Eventual Consistency를 맞추는 것에 적합한 형태이다.
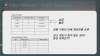
이력정보 테이블을 따로 관리해서 문제가 발생된 부분을 확인한다.
굉장히 많은 데이터를 가지고 있게 된다.
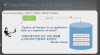 이벤트가 발생되면 이러한 이벤트를 순서에 따라 보관하는 것이 이벤트 소싱이다.
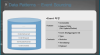 이벤트의 정의는 계속해서 Appending을 하기 때문에 연속성이 있는 데이터이다.
 이벤트가 저장이되지만 상태정보를 가지고 있지 않기 때문에 저장된 이벤트를 꺼내서 리플레이 하는 형태로 처음시작부터 끝 부분까지 상태를 열어서 확인해야 한다.

계속해서 특정 저장소에 저장하게 되면 부하가 발생될 수 있기 때문에 인메모리 영역에 스냅샷을 해서 저장한다.
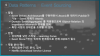 이벤트는 비즈니스 단위의 데이터이다.
런닝 커브가 크고, 쿼리를 하는데 약점이 있다.
특정 구간에 부하가 발생되는데, 추천이나 분석 audit 부분에 부하가 발생이 많이 발생되기 때문에 이러한 부분을 CQRS하는 것을 고민한다.
 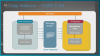 CQRS는 단순히 조회 전용 디비를 분리하는 것이 아닌, 마이크로서비스 아키텍처 특징으로 조인이 되지 않는 데이터들을 이벤트 기반으로 전달 받고, 이러한 것을 Metarial View로 만들어 놓는 것을 말한다. 이런 것을 Event Projection이라고 명칭한다.
따라서, 조회 전용 뷰를 생각하고 만들어내는 방법이 CQRS, Event Sourcing 이다.
 예제 소스 코드
기존 예제 코드는 없어서 따로 따온다.
https://github.com/ddd-newbie/food-delivery
 테스트는 기존 테스트 방식과 달라지는 점이 서비스 간 서비스 호출이 있기 때문에, 이러한 것들을 테스트 하기가 쉽지 않기 때문에, 마틴 파울러는 최대한 유닛테스트를 많이 작성하라고 조언했다고 한다.
 서비스가 서비스를 호출하면서 각각의 트레이스 를 할 수 있는 것이 필요한데 이러한 것으로 zipkin을 사용하면 좋다.
머릿속에 다이어그램을 기억하자.
 하지만 이런 것들이 모두 만병통치약은 아니다.
적절하게 경험해가면서 조절해라.
 마이크로서비스를 도입하는 것은 여정이다. 점점 추가하는 것이고, 애플리케이션을 단계적으로 접근하는 것이 좋다. 빅뱅 방식으로는 쉽지 않다.