Java Reactive Streams
Project Reactor
Reactor는 JVM위에서 효율적으로 요청을 관리할 수 있는 온전한 논블로킹 반응형 프로그램 입니다. 이것은 Java 8의 함수형 API에 특히 CompletableFuture, Stream, 과 Duration으로 통합되었습니다. 이것은 비동기 순차 API Flux( N개의 요소) 와 Mono(0또는1) 를 구성할 수 있도록 제공해준다. 더 넓게는 reactive Streams 명세에 맞춰 구현되어 있다. [Reactive Streams](https://www.reactive-streams.org/]
또한, Reactor reactor-natty 프로젝트를 통해 non-blocking 과 inter-process 통신을 지원한다.
마이크로서비스 아키텍처에 어울리고 Reactor Netty HTTP, TCP, UDP 네트워크 엔진에 backpressure-ready 제공해준다.
Prerequisites (전제조건)
Reactor Core는 Java 8이나 상위 버전에서 동작한다.
org.reactivestreams:reactive-streams:1.0.2. 에 의존한다.
BOM의 이해
Reactor 3 알루미늄 릴리즈 트레인과 함께 reactor-core 3.0.4 BOM 모델을 사용한다.
BOM은 (Bill of Materials) 자체 버전이다. code name을 따르는 것이다.
Reactor 시작
앞서 언급했듯이 Reactor를 핵심으로 사용하는 가장 쉬운 방법은 BOM을 사용하고 프로젝트에 관련 종속성을 추가하는 것입니다. 이러한 종속성을 추가 할 때 BOM에서 버전이 선택되도록 버전을 생략해야합니다.
2.4.1. Maven Installation
The BOM concept is natively supported by Maven. First, you need to import the BOM by adding the following snippet to your pom.xml. If the top section (dependencyManagement) already exists in your pom, add only the contents.
spring-milestones Spring Milestones Repository <https://repo.spring.io/milestone>
Next, add your dependencies to the relevant reactor projects, as usual, except without a **
io.projectreactor reactor-core io.projectreactor reactor-test test
2.4.2. Gradle installation
Gradle has no core support for Maven BOMs, but you can use Spring’s gradle-dependency-management plugin.
First, apply the plugin from the Gradle Plugin Portal:
plugins { id "io.spring.dependency-management" version "1.0.6.RELEASE" }
Then use it to import the BOM:
dependencyManagement { imports { mavenBom "io.projectreactor:reactor-bom:Bismuth-RELEASE" } } 마지막으로 당신의 프로젝트에 아래 dependency를 추가해라.
dependencies { compile 'io.projectreactor:reactor-core' }
Introdution to Reactive Programming
Reactor는 Reactive Programming 패러다임의 구현이다.
아래와 같이 요약될 수 있다.
Reactive programming은 data stream 고려한 비동기적인 프로그래밍 패러다임이다. 이것은 정적 또는 동적인 데이터 스트림을 쉽게 표현할 수 있음을 의미한다. Reactive programming의 첫번 째는, 마이크로소프트 .NET 에코 시스템의 Reactive Extensions 라이브러리가 만들어졌다. 그리고 JVM에서의 reactive programming인 RxJava 가 구현되었다. 시간이 지남에 따라 Reactive Streams의 노력을 통해서 자바를 위한 표준화가 나타나기 시작했고, reactive 라이브러리에 규격화된 interface와 사용 룰이 정의되었다. 이러한 interface들은 java 9의 Flow 클래스 밑으로 통합되었다.
Reactive Programming Paradigm 는 종종 객체지향 언어의 Observer design pattern의 확장으로 표현되곤 한다. 이러한 모든 라이브러리의 Iterable-Iterator 쌍에 대한 이중성이 있으므로 익숙한 반복자 디자인 패턴과 기본 반응 스트림 패턴을 비교할 수도 있습니다. 한가지 크게 다른 점은 iterator는 pull 기반이고, reactive streams는 push 기반이다.
(토비님 강좌 1강 보시면 됩니다.
https://www.youtube.com/watch?v=8fenTR3KOJo&list=PLv-xDnFD-nnmof-yoZQN8Fs2kVljIuFyC&index=10)
값에 접근하는 방법은 전적으로 Iterable의 책임 임에도 불구하고 반복자를 사용하는 것은 필수적인 프로그래밍 패턴입니다. 사실, 개발자는 시퀀스의 next () 항목에 언제 액세스해야하는지 선택해야합니다. 반응 형 스트림에서 위의 쌍과 동일한 것은 게시자 - 구독자입니다. 그러나 구독자에게 새로 사용 가능한 값이 올 때 이를 알리는 것은 게시자이며,이 밀어 내기 측면은 사후 대응의 열쇠입니다. 또한 푸시 된 값에 적용된 연산은 명령형이 아닌 선언적으로 표현됩니다. 프로그래머는 정확한 제어 흐름을 설명하기보다는 계산 논리를 표현합니다.
추가적으로 전달된 값들은 오류 핸들링이나 완료등이 잘 정의된 방식으로 다루어집니다. publisher는 subscriber에게 새로운 값을 넣을 수 있다. 또한 완료나 오류 처리를 알릴 수 있습니다. 또한 오류나 완료도 순차적으로 종료할 수 있습니다. 이것은 다음과 같이 요약될 수 있다.
onNext x 0..N [onError | onComplete] (저걸 풀어서 이야기 하자면, 값들은 onNext로 0개 또는 N개 만큼 불러올 수 있으며, 이것은 onError나 onComplete가 될 수 있다.)
이것은 매우 유연하게 접근할 수 있다. 이러한 패턴은 값이 없거나, 1개이거나 또는 N개인 사용방법을 지원해준다. (무한한 순차 값이나 시간의 틱만큼의 값들을 포함한다)
그러나 첫째로 고려해보자, 왜 우리는 이런 비동기 Reactive 라이브러리가 어디에서 필요할까?
Blocking Can Be Wasteful
현대 응용 프로그램은 많은 수의 동시 사용자에게 다가 갈 수 있으며 현대 하드웨어의 기능이 계속 향상 되더라도 현대 소프트웨어의 성능은 여전히 중요한 관심사다.
그것은 대체적으로 두가지 방법으로 프로그램의 성능의 개선할 수 있습니다.
-
병렬성 : 더 많은 Thread와 더 많은 hardware 자원들을 사용하는 것
-
어떻게 현재 리소스를 더 최적화 할 수 있는지 찾아보는 것.
보통적으로, 자바 개발자들은 blocking code로 프로그램을 작성합니다. 이런 관례는 쓰레드를 추가한다던지, 더 많은 blocking 코드가 작성되면서 성능에 병목현상이 발생될 때까지는 괜찮습니다. 하지만, 자원 활용도의 이러한 확장으로 인해 경합 및 동시성 문제가 빠르게 발생할 수 있습니다.
blocking code는 자원을 낭비한다. 만약 가까이서 본다면, 프로그램은 얼마정도의 레이턴시를 포함하고 있고(notably I/O, such as a database request or a network call), 자원들은 낭비됩니다.그 이유는 쓰레드가 유휴상태가 되어 데이터를 기다리기 때문이다.
그러나 병렬적으로 접근은 실버 룰렛은 아닙니다. 이 것은 필요한 하드웨어의 최대 성능을 따르기 위한 것이고, 또한 자원 낭비에 대해서도 추론 할 수 있고 복잡 할 수도 있습니다.
Asynchronicity to the Rescue?
두번째 최적화 방법은 자원의 낭비하는 것을 해결하는 것입니다. 비동기적인, non-blocking 코드를 작성하여 실행을 동일한 기본 자원을 사용하는 다른 활성 태스크로 전환시킨 다음 나중에 비동기 처리가 완료 될 때 현재 프로세스로 다시 돌아 가게합니다.
그러나 JVM위에서 비동기적인 코드를 어떻게 생산할 수 있을까? 자바는 두가지 비동기적 프로그래밍 모델을 제공한다.
**Callbacks **: Asynchronous 메소드들은 리턴 값을 가지면 안된다. 그러나 추가적인 callback 파라미터로 (람다 또는 익명 클래스) 호출된 결과를 가져가는 것은 가능하다. 잘 알려진 예제로는 Swing’s EventListener 다.
**Futures **: Asychronous 메서드는 Future
이런 기술은 충분할까? 모든 사용방법에 유용하지 않다, 그리고 또한 제약사항을 가지고 있다.
콜백은 콜백 헬과 같이 콜백으로 작성된 코드는 코드를 읽거나 유지보수하는데 어렵다.
하지만 Reactor를 사용하면 간편하다고 보여준다.
( 예제 코드는 무시 )


Future는 콜백보다 조금 낫다. 그러나 Future도 Callback과 마찬가지로 구성하는데 적합하지 않다, 그럼에도 불구하고 Java 8에서는 CompletableFuture로 개선되어졌다.
여러 Future를 함께 사용하는 것은 가능하지만 쉽지 않습니다. 또한, Future는 다음과 같은 문제를 가지고 있다. future는 get() 메서드를 호출하는 것으로 Future 객체와 또 다른 블로킹 상황을 일으키기 쉽다. 지연 연산을 지원하지 않으며 다양한 값과 더 나은 오류 처리를 지원하지 않습니다.
( -> CompletableFuture thenApply chain 시 catch 부분에 대하여 이야기 하는 것 같음. 이것 때문에 많이 고생했음 -_-;;)
From Imperative to Reactive Programming
(명령형 프로그래밍에서 반응형 프로그래밍으로)
Reactive 라이브러리들은 고전적인 비동기 접근 방식의 문제점들을 다루고 있다.
또한 몇가지 추가 측면에 초첨을 맞추고 있다.
-
결합성과 가독성
-
풍부한 어휘로 조작되는 데이터 흐름
-
당신이 구독 할때까지 아무일도 발생하지 않는다.
-
역압 또는 생산자에게 배출 속도가 너무 높다는 신호를 보내는 능력
-
동시성에 의존하지 않는 높은 수준이지만 높은 가치의 추상화
Composability and Readability
결합성이란 의미는 다양한 asynchronous 작업을 조직적으로 구성하는 능력을 말합니다. 이전 작업에서의 결과를 사용하고 그다음 작업에 입력값으로 넣어주거나 또는 fork-join 스타일로 여러 작업을 실행하거나 상위 레벨 시스템에서 비동기 태스크를 개별 컴포넌트로 재사용 할 수 있습니다.
작업을 조직할 수 있는 능력은 코드의 가독성과 코드 유지보수성과 밀접한 연관이 있다. 계층적인 asynchronous 처리들은 갯수만큼 복잡성을 증가시킨다, 코드를 작성하고 읽는 것은 점차 어려워지고 있습니다. callback 모델은 단순합니다, 그러나 이것은 다음과 같은 결점이 있습니다. 복잡한 처리, callback 으로 부터 처리된 callback이 반드시 필요하거나, 내부적인 다른 callback과 중첩되어 있는 것들이다. 이것은 잘알려진 복잡한 Callback Hell 이다. 당신은 이러한 상황이 왜 어렵게 만드는 것인지는 (경험으로부터) 이유를 알 수 있을 것이다.
Reactor는 풍부한 구성 옵션을 제공합니다. 코드는 추상적인 프로세스의 구성을 반영하고 모든 것이 일반적으로 동일한 레벨 (중첩이 최소화 됨)로 유지됩니다.
The Assembly Line Analogy (조립 라인 유추)
당신은 조립 라인을 통해 전달되는 reactive application의 데이터 처리에 대해 생각할 수 있습니다. Reactor는 workstations 또는 컨베이어 벨트 입니다.원재료는 원산지 (원본 발행인)에서 쏟아져 최종 제품으로 소비자 (또는 구독자)에게 보낼 될 준비가됩니다.
원 재료는 다양한 변환과 처리 단계 또는 큰 조립 라인을 통과할 수 있습니다. 만약 결함이 있거나 한 지점에서 막히면 (아마도 복싱 제품이 과도하게 오랜 시간이 걸립니다), 워크 스테이션은 원료 흐름을 제한하기 위해 업스트림 신호를 보낼 수 있습니다.
Operators
Reactor 안에서 Operator들은 우리의 어셈블리로 비유 할 수 있다. 각 operator 는 publisher의 행동을 추가할 수 있고, 새로운 인스턴스 안에 Publisher 이전 단계를 감쌀 수 있습니다. 이러한 체인은 첫번째 퍼블리셔로부터 시작된 데이터가 각 링크에 의해서 변환되고 다음단계로 이동하면서 연결되어진다. 결국엔 구독자는 처리를 완료한다. 되새겨야 하는 부분은 subscriber가 publisher를 구독할 때까지 아무일도 발생되지 않는다는 것이다. 이것을 짧게 줄이면 아래와 같다.
- Operator가 새로운 인스턴스를 만드는 것을 이해하면 체인에서 사용한 연산자가 적용되지 않는다고 생각하는 일반적인 오류를 피할 수 있다.
Reactive Streams 명세서의 어디에도 operator에 대한 명세는 존재하지 않지만, Reactor와 같은 반응 라이브러리의 가장 유용한 가치 중 하나는 그들이 제공하는 연산자의 풍부한 어휘입니다. 이는 단순한 변환 및 필터링부터 복잡한 오케스트레이션 및 오류 처리에 이르기까지 많은 부분을 포함합니다.
Nothing Happens Until You **subscribe()**
Reactor 에서는 publisher 체인을 작성할 때 기본적으로 data를 전송하지 않습니다. 대신에 당신은 추상적인 asynchronous process(재사용 가능하고 조립 할 수있게 도와주는)를 생성합니다.
구독하는 과정에서 게시자를 구독자에 연결하면 전체 체인에서 데이터 흐름이 트리거됩니다.
이것은 내부적으로 subscriber로 부터의 개별 요청에 의해 상위 스트림으로 전파되고 달성하게 되고, 다시 원본 게시자로 돌아갑니다.
Backpressure
업스트림 신호 전파는 배압(backpressure)을 구현하는데도 사용됩니다. 워크 스테이션이 상위 스트림의 워크 스테이션보다 느린 속도로 처리 할 때 회선 위로 보내지는 피드백 신호로 조립 라인(streams?) 유추에 설명되어 있습니다.
이러한 실제 메카니즘은 Reactive Streams 명세에 정의되어 있고 잘 비유되어 있습니다. 한개의 subscriber는 무제한(unbounded) 모드로 동작할 수 있고, 이런 소스가 모든 데이터를 가장 빨리 달성 할 수있게하거나 요청 메커니즘을 사용하여 소스가 대부분의 n 요소에서 처리 할 준비가되었음을 알릴 수 있습니다. 중간 매개자 operator들은 또한 요청이 전달되면서 변경할 수 있습니다. 10개씩 묶어진 buffer가 동작하는 것을 생각해보자. 만약 subscriber 요청당 1개의 buffer라면, 10개의 요소를 생산하는데 적합할 것이다. 일부 운영자는 요청 (1) 왕복을 피하고 요청하기 전에 요소를 생산하는 데 너무 많은 비용이 들지 않는 프리 페칭 전략을 구현합니다.
이런 변환은 모델 안쪽에 push-pull hybrid 형태로 만약 요소들이 읽을 수 있는 상태라면 상위 스트림으로부터 하위 스트림으로 n개의 요소만큼 가져올 수 있다. 그러나 요소가 준비되지 않은 경우에는 제작 될 때마다 상류쪽으로 밀어 넣습니다.
Hot vs Cold
Rx 와 유사한 reactive libraries, reactive sequences의 2가지 주된 카테고리로 구별할 수 있습니다. hot과 cold 같은. 이러한 구분은 reactive stream이 subscriber와 어떻게 반응하는지와 관련이 있습니다.
- Cold 시퀀스는 각 subscriber를 위해서 데이터 소스를 포함하여 새로 시작합니다. 예를들어 만약 소스가 HTTP call에 감싸져 있다면, 각 subscription을 위하여 새로운 HTTP 요청을 만듭니다.
- Hot 시퀀스는 각 구독자에 대해 처음부터 시작하지 않습니다. 오히려, 늦은 subscriber는 그들이 가입 한 후에 방출되는 신호를 수신합니다. 그러나 일부 reactive stream은 전체 또는 부분적으로 배출 기록을 캐시하거나 재생할 수 있습니다. 일반적인 관점에서 볼 때 subscriber가없는 경우 핫 시퀀스를 내보낼 수도 있습니다 ( “구독하기 전에는 아무 일도 일어나지 않습니다”규칙).
출처
https://grokonez.com/java/java-9/java-9-flow-api-reactive-streams
https://projectreactor.io/docs/core/release/reference/#intro-reactive
https://www.youtube.com/watch?v=bc4wTgA_2Xk&list=PLv-xDnFD-nnmof-yoZQN8Fs2kVljIuFyC
4. 리액터 핵심 특징(Reactor core features) 상당 의역.
리액터 프로젝트의 주된 구조는 리액터-코어(reactor-core)로, Java8을 타겟으로 하며 리액티브 스트림 명세에 집중한 리액티브 라이브러리다.
리액터는 퍼플리셔 역할을 하는 플럭스와 모노 두 타입을 제공한다. 플럭스 객체란 0..N개의 반응형 항목 순서에 대응하는 개념이며, 모노 객체는 단일 값이거나 값 없음(0..)의 결과에 대응하는 개념이다.
이 구분을 통해 비동기 처리의 단위가 되는 개념들을 플럭스와 모노로 표현할 수 있다. 예를 들자. HTTP 요청은 유일한 응답만을 생성한다. 따라서 숫자를 셈하는 연산에는 적합하지 아니하다. 그렇기에 이러한 HTTP 요청은 결과를 모노로 표현할 수 있다. 이는 플럭스로 표현하는 것보다는 적합하다. 왜냐면 모노가 없거나 유일한 결과를 다루는 모델이기 때문이다.
처리 카디널리티가 변하는 연산 또한 두 타입으로 표현할 수 있다. 즉, 가령 카운트 연산은 플럭스를(여러 값들이 필요) 통해 수행되지만 그 결과는 모노(합계는 한개)를 통해 표현될 수 있는 것처럼 말이다.
역자: 여기서 이해가 잘 안되는 부분은 카디널리티라는 부분이다. 여기서 카디널리티는 단위 원소수라는 것으로 집합수(원소수)를 의미한다. 그저 특정 연산(가령 메서드)이 수행되는데 관여되는 데이터가 N개이면 그 연산의 카디널리티는 최대 N개가 되는 식이다. 즉 연산에 관계된 데이터가 0개 이상이면 플럭스로 나타내고 0 또는 1개이면 모노로 표현하면 된다는 내용 같다(틀리면 수정 부탁드립니다).
플럭스, 0~N개의 항목에 대한 비동기 순열
 플럭스 Flux는 Publisher로, 0 ~ N 개의 순열을 방출하거나 완료 신호를 받아 종료되기도 하고 에러로 종료되기도 한다. 이는 리액티브 스트림 명세에 따르면 각각 뒤에 연결된 구독자(Subscriber)의 onNext, onComplete, onError에 대응한다.
플럭스는 다양한 범주의 신호를 사용하는 다목적용 리액티브 타입이다. 모든 이벤트 혹은 심지어 종료 이벤트들을 사용하는 건 선택적이다 - onNext 이벤트 없이onComplete 이벤트로 빈(empty) 유한한 순열을 표시할 수도 있으며 여기에 onComplete 이벤트도 제거하면 무한한 비어 있는 순열을 얻게 된다(딱히 유용하지 않으며, 취소 관련한 테스트에나 쓸 법하다). 유사하게 무한한 순열은 꼭 비어 있을 필요는 없다. 가령, Flux.interval(Duration)는 Flux을 생성하며 이는 무한하고 클렁당 정기적인 틱을 발생시킨다.
모노, 비동기적인 0-1 결과
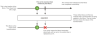 모노 Mono는 특화된 Publisher이며 최대 1개 아이템만을 방출하고 onComplete 신호나 onError 신호와 함께 선택적으로 종료된다.
모노는 플럭스가 제공하는 연산집합의 부분만을 제공하며, 일부 연산은 플럭스를 리턴하는 연산이다(주로 모노를 다른 Publisher와 결합하는). 예를 들어, Mono#concatWith(Publisher)는 플럭스를 리턴하며 Mono#then(Mono)는 또다른 모노를 리턴한다.
모노는 값이 없는(?) 비동기 프로세스를 표현하는데 쓰일 수 있으니 명심하시고, 그런 프로세스는 완료의 의미만을 갖는다는 사실을 적시하시오(Runnable과 유사). 이거 만드려면 Mono
4.3 플럭스와 모노를 만드는 기본 방법 그리고 그것을 구독하는 법
플럭스와 모노를 사용해보는 가장 쉬운 방법은 그들 각자 클래스들의 수많은 팩토리 메서드 중 하나를 사용해보는 것이다.
예를 들자꾸나. 문자열(String)의 순열을 생성하기 위해서는 그저 열거하거나, 컬렉션에 다 넣고 그 컬랙션을 기반으로 플럭스를 만들어 볼 수 있다. 아래와 같이.
Flux seq1 = Flux.just("foo", "bar", "foobar"); List iterable = Arrays.asList("foo", "bar", "foobar"); Flux seq2 = Flux.fromIterable(iterable); 또는 아래와 같이 할 수 있다.
Mono noData = Mono.empty(); [1] Mono data = Mono.just("foo"); Flux numbersFromFiveToSeven = Flux.range(5, 3); [2] [1] 팩토리 메서드가 비어 있더라도 제네릭 타입을 기술해야 한다.
[2] 첫 파라미터는 시작 인덱스이고 두번째는 몇 개를 생산할지에 대한 인자이다.
이제 구독에 대해 살피자. 플럭스와 모노는 자바 람다식을 활용할 수 있다. subscribe() 메서드의 수많은 변형을 사용할 수 있다. 변형이란 수많이 오버로드된 메서드들이다.
subscribe(); [1] subscribe(Consumer consumer); [2] subscribe(Consumer consumer, Consumer errorConsumer); [3] subscribe(Consumer consumer, Consumer errorConsumer, Runnable completeConsumer); [4] subscribe(Consumer consumer, Consumer errorConsumer, Runnable completeConsumer, Consumer subscriptionConsumer); [5] 1] 구독과 동시에 순열을 트리거하오.
[2] 각각 값이 생산될 때마다 작업을 개시한다오.
[3] 값을 다룰 때 에러에도 반응한다오.
[4] 값과 에러를 둘 다 다루는데 순열이 성공적으로 종료된 경우에 부가적인 코드를 수행한다오.
[5] 값과 에러와 성공시 부가적인 코드를 다루는데 subscribe 호출에 관계되었던 Subscription 객체를 기준으로 특정 작업을 수행한다오.
** 이 메서드들의 변형들은 Subscription에 대한 레퍼런스를 리턴하는데 이 레퍼런스로 더 데이터가 필요 없을 때 구독을 취소할 수 있다오. 취소가 이뤄지면, 데이터를 제공하는 측은 값의 생산을 멈추고 초기화했던 자원들을 해제하는 작업을 수행한다오. 이 취소와 클리닝 작업을 위한 다목적 인터페이스인 Disposable 가 존재한다네.
4.3.2 구독 취소와 Disposable**
모든 람다 기반의 subscribe() 메서드들은 Disposable을 리턴한다. Disposable은 구독이 취소될 수 있다는 것을 뜻하며 이는 해당 인터페이스의 dispose() 메서드의 호출함으로써 가능하다. 플럭스와 모노에 있어서, 취소는 데이터 제공자에게 요소의 생산을 멈춰야 한다는 신호를 주는 것과 같다. 그러나 즉발성은 보장되지 않는다. 몇몇 데이터 제공자들은 데이터를 너무 빨리 생산해서 취소 지시가 있기 전에 이미 생산을 마쳤을 수 있다.
Disposables 클래스에는 Disposable 에서 유용한 몇 유틸리티가 있다. 이들 중 Disposables.swap()은 Disposable을 감싸는 Wrapper를 생성하는데, 이를 통해 원자적으로 구체적인 Disposable을 취소하고 교환할 수 있다. 이 기능이 유용할 때가 있다. 그것은, 사용자가 버튼을 클릭할 때마다 요청을 취소하고 새 요청을 만들어야 하는 UI 시나리오와 같은 때이다. Wrapper를 끝내면(Dispose) wrapper는 닫히고, 현재 구체적인 값과 모든 미래에 시도될 치환작업이 종료된다. 또다른 재미있는 유틸리티는 Disposables.composite(…)이다. 서너개의 서비스 콜과 관련된 진행중인 여러 요청과 같은 Disposable을 서너개 모을 수 있으며 나중에 한번에 종료(dispose)할 수 있다. 한번 composite의 dispose()가 호출되면, 이후에 Disposable을 추가하는 시도는 즉시 추가된 Disposable를 종료시킨다.
4.3.3 람다식의 대체 : BaseSubscriber
또 하나의 subscribe 메서드가 있다. 더 일반적이고 구독자를 람다식으로 구성하는 것보다도 더 완벽한 기능을 갖춘 Subscriber다. 이러한 Subscriber를 구현하는 작업을 덜기 위해 확장가능한 클래스 BaseSubscriber가 제공된다.
이들 중 하나를 구현해보자. SampleSubscriber라 명명할 것이며 플럭스에 어떻게 적용되는지 아래에서 살펴본다.
SampleSubscriber ss = new SampleSubscriber(); Flux ints = Flux.range(1, 4); ints.subscribe(i -> System.out.println(i), error -> System.err.println("Error " + error), () -> {System.out.println("Done");}, s -> s.request(10)); ints.subscribe(ss);
이제 SampleSubscriber가 어떻게 생겼는지 보자. BaseSubscriber의 최소한의 구현이다.
package io.projectreactor.samples; import org.reactivestreams.Subscription; import reactor.core.publisher.BaseSubscriber; public class SampleSubscriber extends BaseSubscriber { public void hookOnSubscribe(Subscription subscription) { System.out.println("Subscribed"); request(1); } public void hookOnNext(T value) { System.out.println(value); request(1); } } 이 SampleSubscriber 클래스는 BaseSubscriber를 상속한다. 이는 리액터에서 사용자가 Subscriber를 구독할 때 권장되는 추상 클래스다. 이 클래스는 구독자의 행동을 튜팅할 수 있도록 오버라이딩 가능한 훅을 제공한다. 기본적으로, 이 구독자는 무한한 요청을 보내고 정확하게 subscribe()가 호출된 것과 같이 동작한다. 그러나 BseeSubscriber를 상속하면 요청 횟수를 사용자 정의하고 싶을 때 꽤나 유용하다.
backpressure
backpressure가 동작하는 방식이 단순히 request만 보낸다고 해서 되는 것이 아니라 아래 처럼 subscription에 발행된 메시지가 얼마나 사용되었는지 확인 후 그 다음 요청을 보내는 방식으로 진행할 수 있는 것 같다.
stackoverflow를 해결해준다고 해서 그냥 썻는데 그냥 쓰는게 아닌 느낌적인 느낌
Flux.just(1, 2, 3, 4) .log() .subscribe(new Subscriber() { private Subscription s; int onNextAmount; @Override public void onSubscribe(Subscription s) { this.s = s; s.request(2); } @Override public void onNext(Integer integer) { elements.add(integer); onNextAmount++; if (onNextAmount % 2 == 0) { s.request(2); } } @Override public void onError(Throwable t) {} @Override public void onComplete() {} });
https://www.baeldung.com/reactor-core