Kafka 알아보기 4
현재 구현된 분산 서버 architecture 에서 서버간 통신에 의한 문제가 있었다.
문제의 원인은 아래와 같다.
-
기존에 Redis를 알고 있었고, 서버는 분산 서버 형태로 생각하지 않았다.
-
따라서 각 서버간의 통신 채널은 Redis를 이용하는 것으로 구현되었다.
이후 기존에 클라이언트와 통신 하는 서버와 데이터를 다루는 API 서버 외에 별도의 서버가 필요해짐에 따라 분산 서버간 메시지 송수신 부분이 필요하게 되었다.
하지만, Redis를 사용하여 각 서버 별로 통신하는 것은 한계가 있었다.
한계란 다음과 같다.
-
scale out 되는 서버 중 1 대에만 요청을 보내서 처리를 시켜야 한다.
-
redis에는 pub/sub외에 방법이 없다.
-
http로 쏘는 것을 불허한다.
-
메시지 큐 형태를 사용해야만 안정성이 보장될 것 같다.
위와 같은 요구 사항으로 인하여, Redis로 구현 가능한 한계가 발견되었고, scale out되는 서버에 대하여 Round Robin을 적용시키기 위한 MQ가 무엇일까? 하는 것에 찾아보았다.
기존에 익숙한 Rabbit MQ를 사용해보려 했었다.
하지만 Rabbit MQ로는 실시간 처리에는 불가능 할 것이라는 결론에 도출하였다.
그에 대한 내용은 다음과 같다.
http://kkforgg.blog.me/220965669146?Redirect=Log&from=postView
이러한 상황에서 Zero MQ를 알게되었고, 이것으로 한번 구현해보자고 마음 먹었다.
이유는 브로커가 없는 형태의 MQ같지 않은 MQ다. 라던지
엄청난 속도를 보장한다 라던지
앞서 도큐먼트에서 블라블라 한 이유로 좋다 이런 내용에 따라 적용해서 삽질을 했다.
관련 내용은 아래와 같다.
http://kkforgg.blog.me/220988208507?Redirect=Log&from=postView
zeromq 에서의 Pull/Push 방법이 Round Robin 방식으로 돌아가는 것을 확인하였고, 추가적으로 Router 기능을 제공해 준다는 것을 알게 되어 이때부터 publish / subscribe 와 RR 방식을 적용이 가능 할 것이다라는 것으로 생각하였지만, 별도의 fault-tolerance 확실하지 않다는 것 때문에 온전히 적용은 못했다. 일부 기능에서만 scale out 되는 곳에 적용하였을 뿐, 그 문제점에 대한 확실한 해결책은 되지 못했다.
(zeromq에 대해 약파는 글은 아래를 보라)
https://coolspeed.wordpress.com/2016/03/05/zeromq_fixing_the_world_kr/
이러한 문제로 현재 architecture 내에서 저러한 상황을 피하려 http call도 생겨났고 zeromq 도 혼재되었으며 redis를 이용한 pub/sub도 공존해있다.
(이것은 얼마나 -_- 복잡한 것인가!)
이러한 상황에서 oracle code에서의 아래 독일의 청년이 프리젠테이션을 하는 것을 보던 중. kafka를 보게 되었다.
 (강의 내용은 아래에 저사람 블로그로 있다.)
https://blog.sebastian-daschner.com/entries/event_sourcing_cqrs_video_course
2014년에 나온 카프카 책에 내용을 따르면
** 빅데이터 시대에서 도전 과제는
첫째는 거대한 데이터를 수집하는 것,
두번째는 이 데이터를 분석하는 것.
분석을 위한 목표는
-
사용자 행위 데이터
-
애플리케이션 성능 모니터링 데이터
-
활동 로그 데이터
-
이벤트 메시지
kafka를 통해 정보 소비자는 정보 생성자에 대해 알 필요가 없고, 생산자는 누가 최종 소비자인지 알 필요가 없다.
카프카 디자인은 아래와 같다.
-
비 휘발성 메시지 : 정보 유실 없이 카프카는 O(1) 디스크 구조로 디자인 되어있어, 테라 바이트 단위 이상의 저장 메시지라도 문제 없다.
-
높은 처리량
-
분산
-
다양한 클라이언트 제공
-
실시간 처리
그 밖의 각 역할에 대해서는 document나
http://www.popit.kr/kafka-consumer-group/?fb_action_ids=1433371253444717&fb_action_types=og.comments
위의 링크를 참고해서 확인하면 좋을 것 같다.
그 밖에 리플리케이션에서 토픽에 대한 메시지의 각 파티션은 n개의 레플리카를 가지고 있고, n-1번의 실패까지 메시지 전달을 보장해줍니다. n 개의 리플리카 중 하나의 리플리카는 나머지 리플리카의 리드 리플리카로 행동한다.
현재 document 및 여러 자료들을 확인해서 원했던 RR과 publish/subscribe 관련된 사항에 대해서는 어렴풋하게 알게 된 것 같다.
1개의 Topic을 만들 때 replica와 partition의 갯수를 설정한다.
(이때 partition의 갯수는 증가할 수 있지만 감소 할 수 없기 때문에 partition 갯수를 증가시킬 때는 충분히 고려해서 적용해야 한다.)
(위 링크의 컨슈머 그룹과 topic의 관계를 깊게 보면 좋을 것 같다.)
Round Robin**
scale out 되어진 서버에 메시지를 전달 할 때, Round Robin 방법으로 전달 받기 위해서는 기본적인 partition 갯수를 설정해줘야 하며, partition 갯수 만큼 consumer가 topic에 구독중이면 가장 적절하다. 하지만 partition < consumer 가 많다면 consumer - partition 한 나머지 consumer들은 구독을 하지 않는다.
Publish/Subscribe
1개의 Topic에 Publish/subscribe 형태로 받기 위해서는 consumer가 서로 다른 group.id를 가지고 있어야 할 것 같다.
이러한 테스트 코드는 다음과 같다.
zookeeper와 kafka를 설치해서 가동중이라 가정한다.
bin/kafka-topics.sh --zookeeper zk_host:port--create --topic my_topic_name --partitions 3 --replication-factor 2 topic을 kafka에 생성한다.
Consumer
public class ConsumerTest implements Runnable { private int consumerNumber; public ConsumerTest(int number) { this.consumerNumber = number; } public int getConsumerNumber() { return consumerNumber; } public void setConsumerNumber(int consumerNumber) { this.consumerNumber = consumerNumber; } public Properties consumerProps() { Properties props = new Properties(); props.put("bootstrap.servers", "broker : localhost:9092"); // kafka props.put("group.id", "tester"); // group id //props.put("auto.commit.interval.ms", "1000"); props.put("enable.auto.commit", "false"); //props.put("session.timeout.ms", "10000"); //props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.RoundRobinAssignor"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //props.put("value.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer"); return props; } public static void main(String[] args) { int numConsumers = 2; ExecutorService executor = Executors.newFixedThreadPool(numConsumers); for(int i = 0 ; i consumer = new KafkaConsumer<>(consumerProps()); consumer.subscribe(Arrays.asList("my_topic_name")); /**/ while (true) { ConsumerRecords records = consumer.poll(100); for (ConsumerRecord record : records) { System.out.println("this consumer number " + this.consumerNumber + " > " + record.toString()); } consumer.commitSync(); //consumer.close(); } /* */ } } 3개의 partition을 생성했기 떄문에 3개의 consumer와 producer로 예제가 작성되어져있다.
Producer
public class ProducerTest implements Runnable { private int producerId; public ProducerTest(int number) { this.producerId = number; } public static void main(String[] args) throws Exception { int count = 3; ExecutorService executor = Executors.newFixedThreadPool(count); for (int i = 0; i producer = new KafkaProducer<>(producerProperties()); int i = 0; while (true) { producer.send(new ProducerRecord("my_topic_name", "oauthToken" + (i++), "aaaa" + (i++))); try { TimeUnit.SECONDS.sleep(5); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } public int getProducerId() { return producerId; } public void setProducerId(int producerId) { this.producerId = producerId; } public static class SimplePartitional extends DefaultPartitioner { private int num; @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List partitions = cluster.partitionsForTopic(topic); return (num+++1) % partitions.size(); } } } 이때 Topic으로 메시지 보낼 때 key값을 계속 변경해서 보내줘야 한다. 그 이유는 동일한 key값으로 보내면 1개의 partition으로만 메시지가 전달된다. 따라서 전달할 메시지 key를 바꿔줘야 한다.
Consumer에서 Partition으로 넣는 전략 부분이 있는데 default로 잡혀 있는 것은 아래를 참고하길 바란다.
public class DefaultPartitioner implements Partitioner { private final ConcurrentMap topicCounterMap = new ConcurrentHashMap<>(); public void configure(Map configs) {} /** * Compute the partition for the given record. * * @param topic The topic name * @param key The key to partition on (or null if no key) * @param keyBytes serialized key to partition on (or null if no key) * @param value The value to partition on or null * @param valueBytes serialized value to partition on or null * @param cluster The current cluster metadata */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null) { int nextValue = nextValue(topic); List availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { // no partitions are available, give a non-available partition return Utils.toPositive(nextValue) % numPartitions; } } else { // hash the keyBytes to choose a partition return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } } private int nextValue(String topic) { AtomicInteger counter = topicCounterMap.get(topic); if (null == counter) { counter = new AtomicInteger(new Random().nextInt()); AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter); if (currentCounter != null) { counter = currentCounter; } } return counter.getAndIncrement(); } public void close() {} }
위와 같이 테스트를 해보면 Round Robin으로 메시지가 수신되는 것을 확인 할 수 있다.
그 밖에 별도의 partition 전략을 작성해서 넣을 수도 있다.
현재 이러한 kafka를 이용하여 메시징 시스템을 구축하고, logstash로 log를 수집하던 것을 kafka로 수집하게 된다면, 복잡한 architecture가 단조롭게 변경될 것이라고 생각한다.
현재 남은 것들은 이러한 부분들이 남아 있다.
- stream 활용.
비동기식 애플리케이션의 근본적인 문제는 현재 상황을 나타내는 테이브를 현재 일어나는 일에 대한 이벤트 스트림과 결합시키는 것이다.
트랜잭션 로그는 데이터 베이스에 대한 모든 변경사항을 기록합니다.
고속 추가 기능만 로그를 변경할 수 있습니다. 이 관점에서 볼 때
데이터 베이스의 내용은 로그에 최신 레코드 값을 캐싱합니다.
진실은 로그 입니다. 데이터 베이스는 로그의 서브 세트의 캐시 입니다.
캐쉬된 하위 집합은 로그의 각 레코드 및 인덱스 값을 최신 값입니다.
Stream으로 할 수 있는 것은 Topic에 대한 record를 가공하는 것이다.
우선 예를 들자면, Topic 내에 로그를 쌓는다고 했을 때 로그 데이터를 검색하는 것을 kafka에서 자체적으로 제공해주지 않는다. 따라서 Topic에 쌓인 record를 처음부터 읽어가면서 맞는 것이 나올 때 까지 뒤지다가 주는 형태로 가져올 수 있는 것 같다.
따라서 로그성 데이터를 처리하기 위해서는 Stream을 이용하여 그 로그 데이터를 가공. 별도의 query가 가능한 곳으로 옴길 수 있도록 만드는 것으로 활용 될 것 같다.
주로 로그를 이용하여 통계자료나 특정 데이터를 추출하는 것에 Stream을 이용하여 처리하는 것으로 보인다.
Topic Replication
topic의 partition의 log를 복제한다.
leader는 partition의 갯수 참고하여 선출된다.
partition은 1개의 리더와 0<= follow를 갖을 수 있다. 모든 읽고 쓰기를 담당하는 것은 leader replication이다.
1번의 실패를 허용하려면 3개의 복사본이 필요하다.
2번의 실패를 허용하려면 5개의 복사본이 필요함. 하지만 HDD의 성능을 바라보고 설정하는 것을 이야기 한 것 같다. 2번의 실패를 위해서 5번의 copy가 일어나는 것이 맞느냐 하는 문제 같은 것이다.
Kafka의 replication은 kafka instance 수로 조절 할 수 있다.
따라서 3개의 replication을 구성하겠다고 하면 kafka instance는 2개 이상이여야 한다.
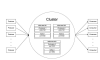
위에서 kafka-test-001 이 각 kafka server이다 이때 여기를 살펴보면, zookeeper와 kafka 가 한 묶음으로 되어 있는데, 이것은 곧 1개의 kafka instance를 올릴 때 1개의 zookeeper가 같이 물려 있어야 한다는 것이다.
kafka의 topic들은 zookeeper에 노드에 저장된다. (/brokers 에 저장된다, 따라서 topic 정보들을 날릴려면 /brokers 노드를 날려버리면 된다.)
그렇기 때문에 3개의 replication을 구성하기 위해서는 3대의 zookeeper와 3대의 kafka instance가 필요하다. 권장 사항으로는 동일 인스턴스가 아닌 각각의 인스턴스에 올리는 것으로 한다.
우선 zookeeper cluster를 구축해야 하며, 이후 kafka cluster를 설정해야 한다.
zookeeper cluster는 아래 링크를 참고하면 된다.
https://zookeeper.apache.org/doc/r3.3.2/zookeeperAdmin.html
ZooKeeper Administrator’s Guide
Deployment System Requirements Supported Platforms Required Software Clustered (Multi-Server) Setup Single Server and Developer Setup Administration Designing a ZooKeeper Deployment Cross Machine Requirements Single Machine Requirements Provisioning Things to Consider: ZooKeeper Strengths and Limita
zookeeper configuration file에 아래와 같이 3대의 서버들을 등록해야 하며,
tickTime=2000 dataDir=/var/zookeeper/ clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888 각 서버 별로 아래와 같이 설정을 해줘야 한다.
echo 1 > /tmp/zookeeper/myid 본인이 구성시에는 myid에 관련된 오류가 발생하였다.
(찾던 중 각 서버 별로 1,2,3을 설정해줘야 했다. aws ec2 ubuntu 14.x)
이후 kafka 설정 파일에서는 아래와 같이 설정한다.
broker.id=1 #각각 다르게 입력해야 한다 zookeeper.connect=zoo1:2181,zoo2:2181,zoo3:2181 #zookeeper cluster를 건 3대에 대한 정보를 입력해야한다. 클러스터 된 zookeeper 정보를 입력 해야 하며, 이후에 zookeeper를 올린 뒤 kafka를 실행시키면 정상적으로 구동되는 것을 확인 할 수 있다.
3개의 클러스터를 적용한 topic을 생성 명령어는 아래와 같다.
bin/kafka-topics.sh --zookeeper zk_host:port--create --topic my_topic_name --partitions 4 --replication-factor 3 위에서 partition을 4개 replication을 3으로 걸어두었는데, 위에 작성한 토픽은 4개의 scale out된 서버가 같은 consumer-group으로 topic으로 붙으면 파티션을 갯수대로 각각 바라보게 된다. 따라서 1개의 메시지를 발행하여 scale out된 서버 중 1대에만 전달되야 할 때가 필요했기 때문에 구성하였다.
이후 내용들은 추가적으로 이슈가 발생되면 덧붙이도록 하겠다.